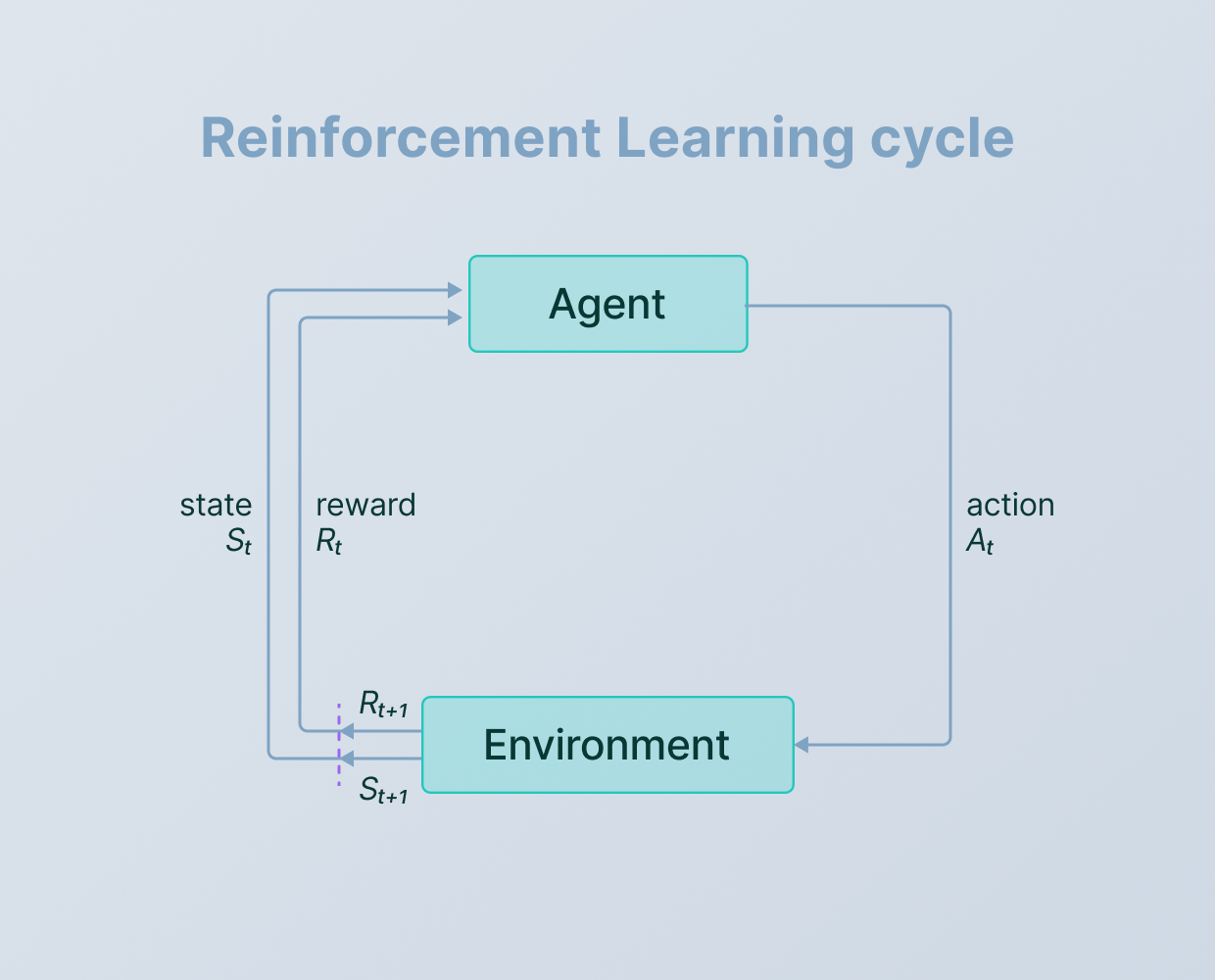
Reinforcement Learning should be better seen as a “fine-tuning” paradigm that can add capabilities to general-purpose foundation models, rather than a paradigm that can bootstrap intelligence from scratch.
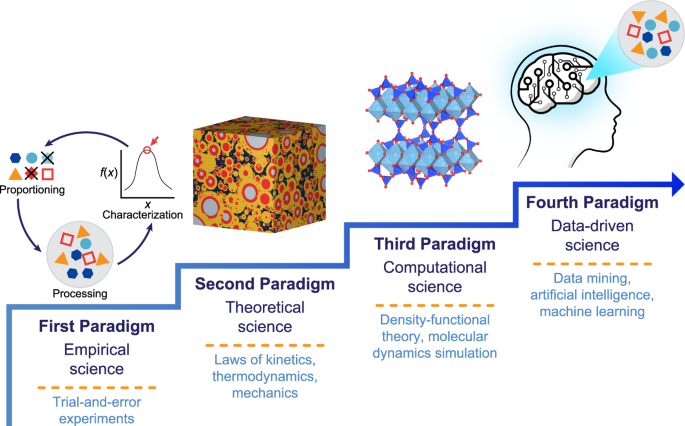
Machine learning in concrete science: applications, challenges

5: GPT-3 Gets Better with RL, Hugging Face & Stable-baselines3, Meet Evolution Gym, Offline RL's Tailwinds, by Enes Bilgin, RL Agent
Deep Reinforcement Learning: Definition, Algorithms & Uses
RAG Vs Fine-Tuning for Enhancing LLM Performance - GeeksforGeeks

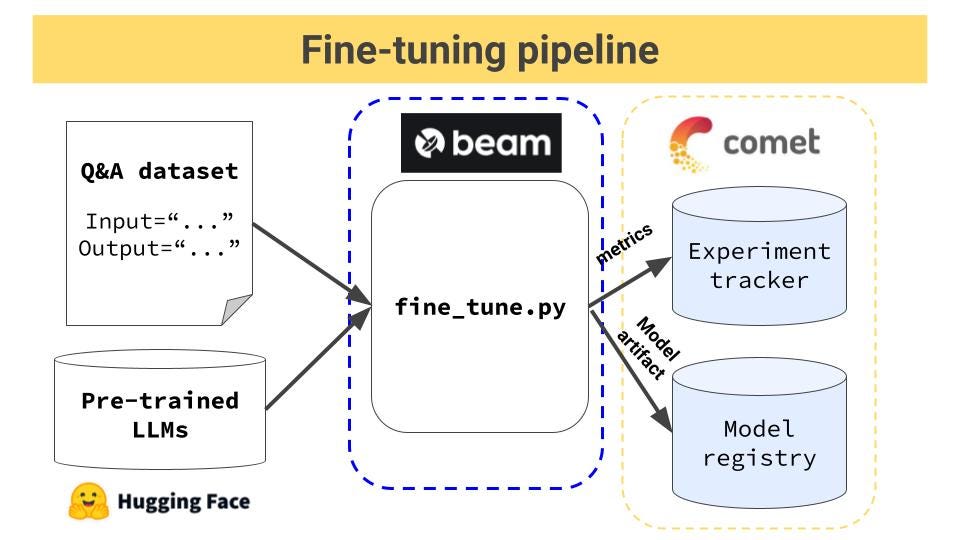
Fine-tuning 20B LLMs with RLHF on a 24GB consumer GPU

Google's Universal Pretraining Framework Unifies Language Learning

How Reinforcement Learning from AI Feedback works

Fine-tuning 20B LLMs with RLHF on a 24GB consumer GPU

AI, Free Full-Text
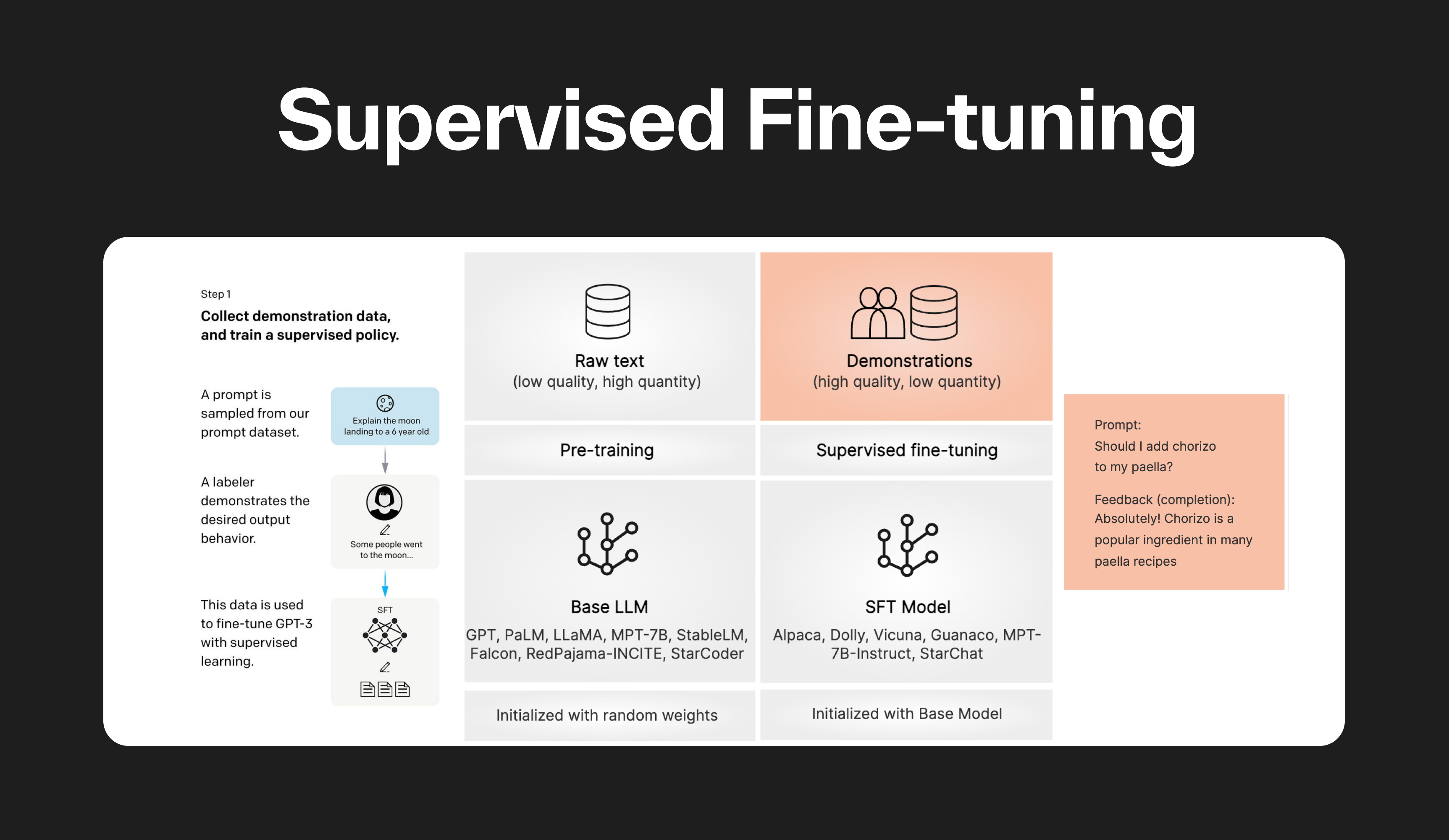
What is supervised fine-tuning? — Klu

25 Machine Learning Projects for All Levels